Loss Function은 W가 정량적으로 얼마나 나쁜지를 나타냅니다.
Optimization procedure는 모든 가능한 W를 탐색해서 least bad인 걸 찾아내는 과정입니다.

CIFAR-10에서 y의 범위는 1~10 사이의 정수 (1,2,3,4,5,6,7,8,9,10) loss function L_i, L_i 는 함수 f 와 y를 비교합니다.
마지막으로 모든 i들의 score를 합산해 평균을 낸 것이 L 입니다.
Multi-Class SVM Loss

정답 카테고리인 y_i를 제외한 나머지 카테고리들과 비교해 나온 값들을 전부 더하여 Loss L_i를 만듭니다. 정답 카테고리의 점수가 우리가 설정해놓은 safety margin 1을 포함해 오답 카테고리 점수보다 크다면 정답 카테고리에 대한 점수가 거짓 카테고리보다 훨씬 더 크다는 것이고 loss는 0이됩니다. 위 방식으로 모든 카테고리와 비교한 값을 다 더하면 이 데이터셋에서 하나의 example에 대한 최종 loss값을 얻게됩니다. 이후 모든 L_i를 더해 평균 내면 전체 데이터셋에 대한 Loss 값을 얻을 수 있습니다.
if then notation을 max(0, sj-syi+1)처럼 컴팩트하게 만들 수 있습니다. 하지만 이런 notation은 이해하기에 혼란스러울 수 있어서 case based notation으로 쓰는 게 도움될 수 있습니다.

위의 Multiclass SVM loss 같은 스타일의 손실함수를 hinge loss 라고 부릅니다. 그래프가 비슷한 느낌으로 생겨서 그렇습니다. s_yi에 대응하는 x축이 정답 클래스에 대한 점수고 y축은 loss입니다. loss 가 선형적으로 줄다가 우리가 결정한 safemy margin에 도달한 이후에는 0이됩니다.
true score가 다른 스코어보다 훨씬 더 높으면 해피해피하지만 만약 true score 가 충분히 높지 않다면 loss가 발생합니다.

car에 대한 loss 값을 계산해보면
max(0, 1.3 - 4.9 + 1) + max(0, 2.0 - 4.9 + 1) = 0 + 0 = 0
frog에 대한 loss 값을 계산해보면
max(0, 2.2 - (-3.1)) + max(0, 2.5 - (-3.1)) = 6.3 + 6.6 = 12.9

Q. 어떻게 +1이란 값을 얻은걸까?
A. 손실 함수에서 나타나는 유일한 상수값이라 좀 뭔가 요상한 느낌이 들지만 어느 정도의 임의적인 선택입니다. 왜냐면 우리는 손실 함수에서 점수의 절대적인 값에 대해서는 신경 쓰지 않고 점수 간의 상대적 차이에만 신경을 씁니다. 우리는 정답 점수가 오답 점수보다 크다는 것에만 신경을 씁니다. 따라서 실제로 전체 W를 위아래로 스케일링한다고 상상하면 모든 점수가 그에 맞게 재조정됩니다.
Q. 자동차의 점수(4.9)가 조금 바뀌게 된다면 loss 값을 어떻게 될까?
A. car score는 이미 다른 스코어보다 훨씬 높기 때문에 변하지 않습니다.
Q. Loss 값의 최대값과 최소값
A. min -> 0, max -> infinity
Q. 초기화 시에 W의 값은 매우 작아서 score들이 0과 가깝게 나올텐데 그렇다면 그 때의 loss는 어떨까?
A. (클래스의 수) - 1
자기 자신을 제외한 나머지 클래스들을 계산하기 때문에. margin인 1만 남게될테고 그렇게 계산하면 (c-1) * c / c 나옵니다. 이는 굉장히 좋은 디버깅 방법입니다. 왜냐면 처음 트레이닝할 때 Loss 값은 c-1이 나와야될텐데 그렇지 않으면 버그가 발생한 것이기때문에 코드를 다시 확인해보아야합니다.
Q. j=y_i를 포함해서 모든 클래스에 대해 계산하면 어떨까?
A. Loss 값이 1만큼 오른다. ( (something) + 1 ) * c / c, j=y_i인 점수를 뺀 것은 관습적인 부분입니다. 왜냐하면 가장 작은 loss 값이 1인 것보다 0일 때 더 괜찮아 보이기 때문입니다. 사실 이를 포함하든 안하든 동일한 classifier를 얻게 됩니다
하지만 Loss의 최소값을 0으로 만드려면 제외해야합니다.
Q. 평균을 내지 않는다면 어떨까?
A. 변하지 않습니다. 클래스의 수는 우리가 데이터셋을 선택하기 이전에 고정됩니다. 그래서 mean을 사용하는 것은 단지 loss function을 하나의 상수값으로 rescale 하는 겁니다. 그래서 별로 상관없습니다. 다른 scale하는 것들을 wash out 해버리는 겁니다. 우리는 그 점수들의 진짜 값들 혹은 loss의 진짜 값들에 대해서는 관심 없습니다.
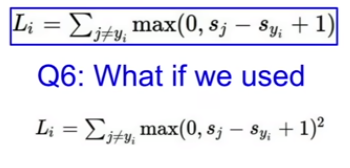
Q. 제곱을 하면 어떨까?
A. 다릅니다.
Q. 제곱하지 않은 Loss 말고 제곱한 Loss를 사용하려면 어떤 점을 고려해야할까?
A. loss function의 가장 중요한 부분은 실수가 얼마나 나쁜지를 정량화하는 것입니다.
squared loss를 사용한다고 했을 때 나쁜 결과에 대해서 non-squared loss보다 더 큰 loss 값을 낼 것입니다. hinge loss를 사용하면 조금 잘못되거나 많이 잘못되는 건 신경 쓰지 않습니다. hinege loss에서는 조금 잘못되면 조금 잘못된 만큼 증가시킵니다. 그래서 squared loss를 쓰냐 non squared loss를 쓰냐는 우리가 얼마나 다양한 종류의 에러에 대해 신경쓰는지에 대해 정량화하는 방법입니다. loss function을 고르는 것은 어떤 종류의 에러가 중요하고 어떤 종류의 에러에 맞써서 trade off 해야하는 지 알고리즘에게 알려주는 것이기 때문에 매우 중요합니다.
Multiclass SVM Loss : Example Code
def L_i_vectoried(x, y, W):
scores = W.dot(x)
margins = np.maximum(0, scores - score[y] + 1)
margins[y] = 0
loss_i = np.sum(margins)
return loss_inp.sum 을 사용하면 모든 벡터의 값을 iterate 하는 것보다 더 좋은 방법입니다.
Q. ㅣ=0인 W를 찾았을 때 이 W가 L=0인 유일한 W인가?
A. 반드시 다른 W가 존재합니다. 2W또한 L=0입니다.

그렇다면 loss 를 0으로 갖는 다양한 버전의 W 중에 우리는 어떤 걸 골라야할까.
사실 우리는 training data에 얼마나 fit한지는 관심없습니다. 우리는 test data에서의 성능을 중요하게 생각합니다.
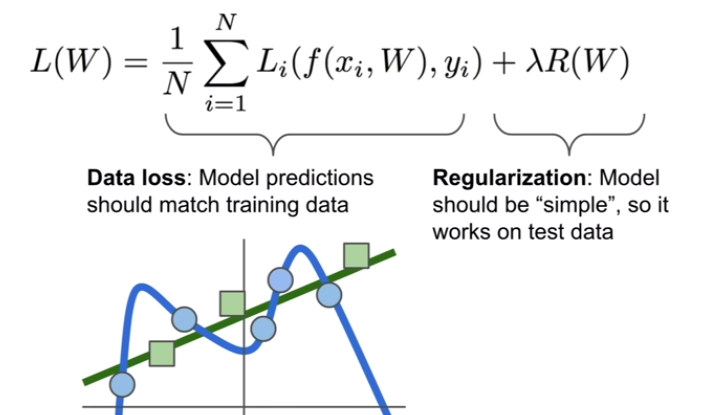
파란색 점들이 traning data라고 할 때, 우리가 classifier에게 모든 점들에 fit하게 하라고 하면 저런 wiggly curve가 나올거고 모든 training data를 완벽하게 classify 할것입니다. 하지만 이건 좋지 않습니다. 우리는 training data에서의 성능을 주요하게 생각하지 않고 test data에서의 성능에 관심있습니다. 그래서 만약 우리가 같은 트렌드를 따르는 초록색 점들을 가져오면 blue line은 완전 틀렸을 것입니다. 오히려 straight line이 더 잘 fit할겁니다. machine learning에서 매우 중요한 얘기이며 우린 주로 이러한 문제를 Regularization이라고 부르는 녀석으로 해결하곤 합니다. loss function에 추가적인 term을 더하는 겁니다. 모델이 더 간단한 W를 고르도록 만듭니다.
Occam's Razor라고 과학적인 발견에서 기반이 되는 아이디어인데 만약 다양한 관찰을 설명할 computing hypothesis를 가지고 있으면 일반적으로 더 단순한 hypothesis를 선호해야합니다. 미래의 새로운 관측을 일반화하기에더 좋은 explanation이기 때문입니다.
그래서 우리는 머신러닝에서 이런 지시를 따르기 위해서 몇 explicit reglularization penalty을 사용합니다. 보통 R이라고 씁니다. 그래서 표준의 Loss function은 data loss와 regularization loss 두개의 terms을 가집니다. 그리고 hyper-parmeter lambda는 둘 사이를 trade off 합니다. labmda는 모델을 training 할때 tune 해야할 주용한 녀석임.
Q. 람다R W가 파란색 선이 초록색 선이 되도록하는데 어떤 연관이 있는걸까?
A. regression 문제를 푼다고 했을 때, 이 Regularization은 너의 모델이 high degree 보다 lower degree polynomial을 선호하게 만들 수 있음. 만약 그게 data에 적절히 fit한다면. 이 규제를 추가하더라도 모델은 여전히 더 높은 degree의 polynomial에 접근할 수 있지만 그 polynomial을 사용하려면 ( 더 복잡한 모델을 사용하길 원하면 )그 penalty를 뛰어넘어야합니다.
자 이제 Regularization은 다음 페이지에서 정리해볼겠습니다.
'인공지능 > cs231n' 카테고리의 다른 글
| [cs231n 정리노트] 4. Back-Propagation & Neural Networks (0) | 2025.03.21 |
|---|---|
| [cs231n 정리노트] 3. Loss Functions and Optimization (3) Optimization (0) | 2025.03.16 |
| [cs231n 정리노트] 3. Loss Functions and Optimization (2) Regularization (0) | 2025.03.10 |
| [cs231n 정리노트] 2. Image Classification (0) | 2025.03.09 |
| [cs231n 정리노트] 0. 시작하기 (0) | 2025.03.09 |